
Watson (IBM) , Siri (Apple), Viv (créé par les inventeurs de Siri), M (Facebook), Cortana (Microsoft), Google Now, Amazon Echo, Samsung S Voice, Evi et Maluuba, Yseop, Digital Genius ? Vous ne les connaissez pas encore mais eux vous connaissent déjà sûrement un peu ! Ce sont les Assistants Personnels Virtuels ou les Compagnaux Digitaux d’un nouveau genre capables de raisonner ultra-rapidement en se basant sur d’immenses bases de données. Un degré supplémentaire de sophistication et de pertinence a été atteint par l’utilisation du Deep Learning.
Le Deep Learning est un des composants de l’Intelligence Artificielle (IA). C’est une des techniques les plus raffinées de Machine Learning, nécessaire pour traiter la Big Data.
En résumé, l’objectif de l’IA est de donner des réponses pertinentes à des requêtes de tout ordre (une traduction, une réservation de billets, un diagnostic médical, un rapport financier, etc…) en utilisant des données brutes et des programmes comme ceux du Machine Learning. Pour l’instant les données brutes que les assistants personnels digitaux peuvent analyser sont
- les éléments visuels (images, photos, vidéos)
- les éléments textuels (mots, chiffres)
- les éléments sonores (parole, musique)
Hhhmmm, mais le Machine Learning, c’est quoi déjà ?
Le Machine Learning est l’ensemble des méthodes pour faire reconnaître aux ordinateurs des objets de tout type (visuel, textuel, sonore) quand ils les trouvent, en établissant eux-mêmes les règles de reconnaissance que les programmeurs ne leur auront pas spécifiées.

Reconnaissance spatiale (Purdue University image/e-Lab)
Il est en effet impossible de créer des règles pour toutes les données existantes, l’ordinateur doit y mettre du sien !
Comme le précise Laurent Massoulié, directeur du centre de recherche commun Inria – Microsoft Research : « Nous ne sommes encore qu’au début du phénomène du déluge de données. (…) Mais il revient à la science informatique de proposer les architectures de réseaux, de centres de traitement de données ou d’informatique dans les nuages sur lesquelles se déversera ce flux de données. (…) L’informatique va aussi développer les algorithmes d’apprentissage automatique qui transformeront les flux de données brutes en informations utilisables. »
John Giannandrea, responsable de l’IA chez Google, résume le Machine Learning en une phrase.
Un programme informatique qui apprend tout seul.
Et alors le Deep Learning dans tout ça ?
Le Deep Learning s’inspire du cerveau humain, en mettant en jeu les réseaux neuronaux convolutifs. Rien de moins.
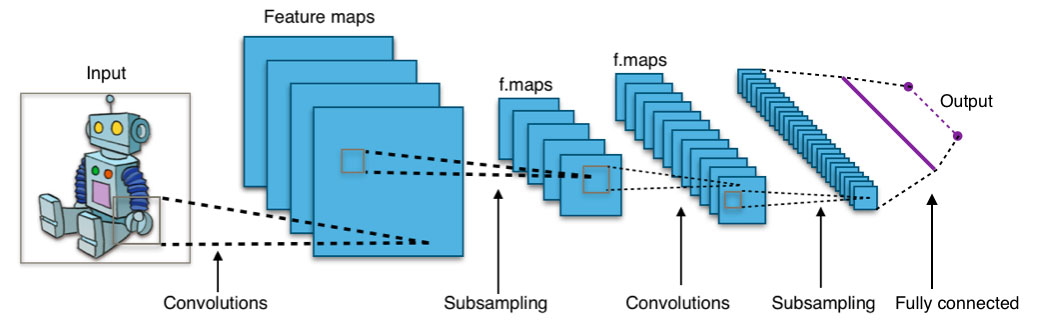
Réseau neuronal convolutif ou ConvNet ou CNN (CC BY-SA 4.0)
Yann Lecun est un chercheur français, spécialiste reconnu de l’IA. Il travaille depuis 2013 comme Directeur du Laboratoire d’IA chez Facebook et sa définition du Deep Learning tient en huit mots :
“cela fonctionne juste comme le cerveau”,
ou en huit autres mots :
“programmes qui apprennent à représenter le monde”,
ou en tout plein de mots :
“constitution de systèmes auto-apprenants, par exemple de reconnaissance de forme ou de tout autre chose, en assemblant de très nombreux modules ou éléments, qui s’auto-forment et s’auto-entraînent suivant le même principe…”

Illustration d’algorithmes de reconnaissance faciale, parue dans une publication Facebook sur l’IA
Le Deep learning est donc un type de Machine Learning dans laquelle les algorithmes détectent petit à petit des règles pertinentes, en étant alimenté par de très nombreuses données.
Le Deep learning est “profond” parce qu’il y a de nombreuses couches successives d’algorithmes, soit de 5 à 20 contre 1 ou 2 auparavant. Les résultats d’une couche alimentent celle d’après, ce qui démultiplie les connexions et les assemblages. Cela aboutit à des reconnaissances successives de caractéristiques de plus en plus complexes et abstraites.
Je l’ai compris comme une déconstruction ordonnée des données brutes pour reconstituer plus facilement et systématiquement un résultat à une requête.
Apprentissage supervisé ou non?
Je voulais aborder une dernière subtilité qui me semblait importante. Les données qui alimentent ces algorithmes peuvent être étiquetées ou non, ou les deux.
Si les données sont taguées, on parle d’apprentissage supervisé. Sinon, on parle d’apprentissage non-supervisé.

Google Brain a fait une percée dans l’apprentissage non supervisé en 2012. Il a été soumis à des millions de données non étiquetées de Youtube et a réussi à comprendre le concept de chat. Alors même qu’on ne lui a donné aucune image de chat étiquetée comme telle, il a su reconnaître dans toutes les données brutes ingérées les têtes de chat.
Malgré cette avancée, aujourd’hui c’est l’alliance des bases de données étiquetées et du deep learning qui est plus efficace que l’apprentissage non supervisé.
Mais dans la vraie vie, ça marche?
Un premier exemple est Smart Reply. C’est l’outil mail développé par Google qui permet de suggérer des réponses automatiques et pertinentes.
La programmation classique ne peut pas proposer des réponses toutes prêtes pour tous les emails arrivant dans une boîte, mais un algorithme qui auto-apprend arrive à résoudre ce problème.
Au fur et à mesure des analyses que l’algorithme fait et engrange sur les conversations, il détermine par lui-même ce que pourrait être une réponse à un mail entrant.
Autre exemple de DeepMind, start-up spécialisée en IA, rachetée en 2014 par Google.L’idée de la démonstration de DeepMind était de confronter le programme à des jeux d’arcade ATARI, en laissant l’IA jouer sans lui donner les règles du jeu au préalable. Partie après partie, le programme tire les enseignements de ses scores au départ très mauvais, pour s’améliorer rapidement, pour battre au final les joueurs humains.
Et je ne pouvais pas ne pas vous parler de Facebook et de M, mon (futur) nouvel assistant personnel dans le Chat Facebook.
M, mon futur nouvel assistant virtuel
Une question s’impose: M, comme Magique ou comme Mouais, faut voir ?
Mais au fait, pourquoi M ?
En terme de déluge de données, on peut convenir que Facebook n’est pas en reste. Il acquiert des tonnes d’information générées par les utilisateurs eux-mêmes. Suivant la logique du monde de Facebook, le défi est de savoir comment utiliser ces données pour satisfaire au mieux l’utilisateur (vous) voire anticiper vos besoins. La réponse est simple : comme le ferait un ami pour vous, qui connaîtrait bien vos goûts et saurait vous comprendre.
Et qui dit réponse simple, dit réseau neuronal convolutif !
Concrètement pour Facebook, le but est de vous proposer le newsfeed le plus approprié (c’est-à-dire affiner Edgerank) et de créer M, votre concierge, ou assistant personnel ou compagnon digital. M est celui qui saura répondre à toutes vos requêtes en s’appuyant sur vos données et de multiples autres bases.
Alex Kantrowitz de Buzzfeed a eu la chance de tester la version bêta de M.
M lui a envoyé des Gif drôles et réconfortants à la demande. Il a su également commander pour son chef des places de cinéma Star Wars, épisode 7, qui n’arrivait pas à en trouver. 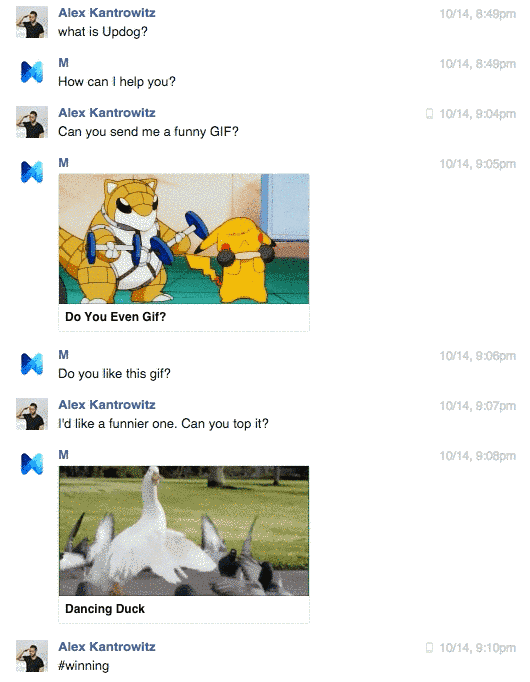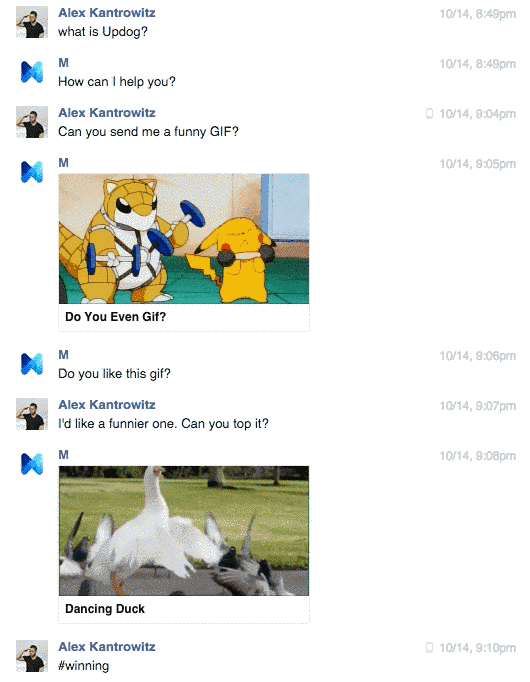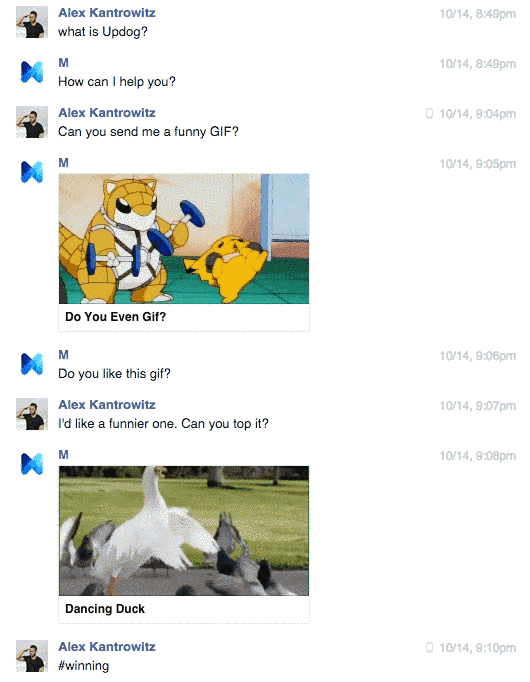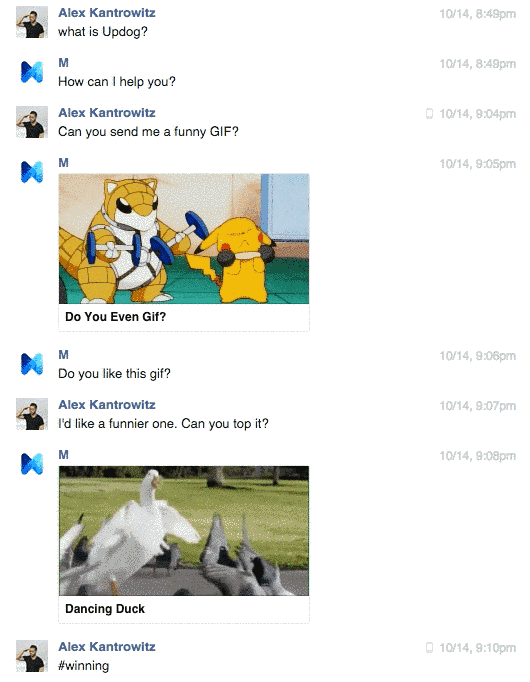

En conclusion ? M s’est avéré “ultra addictif”.
Au passage, ce nouveau mode de recherche sera sérieusement à prendre en compte dans les futures mises en avant des e-commerçants…
C’est bien joli, mais restons calmes !
Certes le Deep Learning s’inspire des réseaux neuronaux du pré-cortex, mais peut-on comparer l’IA à l’intelligence humaine?
Non, il s’agit d’une inspiration et non d’une copie. On est très loin de la conscience.
Se demander si un ordinateur peut penser est aussi intéressant que de se demander si un sous-marin peut nager. (Edsger Dijkstra, mathématicien et informaticien néerlandais)
Si vous aviez une crainte et pour vous confirmer que notre cerveau n’est pas un ordinateur et inversement faites ce petit test!
Test d’intelligence artificielle
Pierre-Yves Oudeyer, Directeur de Recherche à l’INRIA, confirme que « le spectre de ce qu’une intelligence artificielle peut apprendre est très limité. Le mécanisme de l’apprentissage chez l’enfant fait partie des grands mystères scientifiques, on balbutie donc dans la construction de machines dotées de capacités d’apprentissage similaires. (…) on est loin de la flexibilité d’un enfant de 5 ou 6 mois », prévient-il.
Cependant les assistants virtuels sont bel et bien là et vont aller sans cesse en s’améliorant. Dans votre vie personnelle ou professionnelle, vous serez donc bientôt accompagné d’un Assistant Personnel d’un nouveau genre, qui sera capable de s’adapter à vous, de se customiser au fur et à mesure de vos interactions avec lui.
Les gens pourraient commencer à tomber amoureux de leurs partenaires virtuels. (Helen Driscoll Maître de de conférence à l’université de Sunderland)
Mais jusqu’où pourront aller ces interactions. Ne sera-t-il qu’un assistant? A vous de voir, même si à l’instar de Theodore Twombly, vous pourriez envisager une relation plus complexe.






Top